작년 12월에 2주간의 자연어처리(NLP) 관련 학습과 2주간의 NLP 경진대회를 진행하면서, 자연어처리에 대한 다양한 실험과 문제 해결 경험을 쌓을 수 있었다. 올해 초 기업 연계 프로젝트 진행 및 작년 말에 제대로 정리를 못한 2개의 프로젝트를 정리하고자 이렇게 늦게나마 글을 작성하게 되었다.
이번 글에서는 NLP 모델 실험 과정, 성능 최적화, 그리고 배운 점을 정리해보려고 한다.
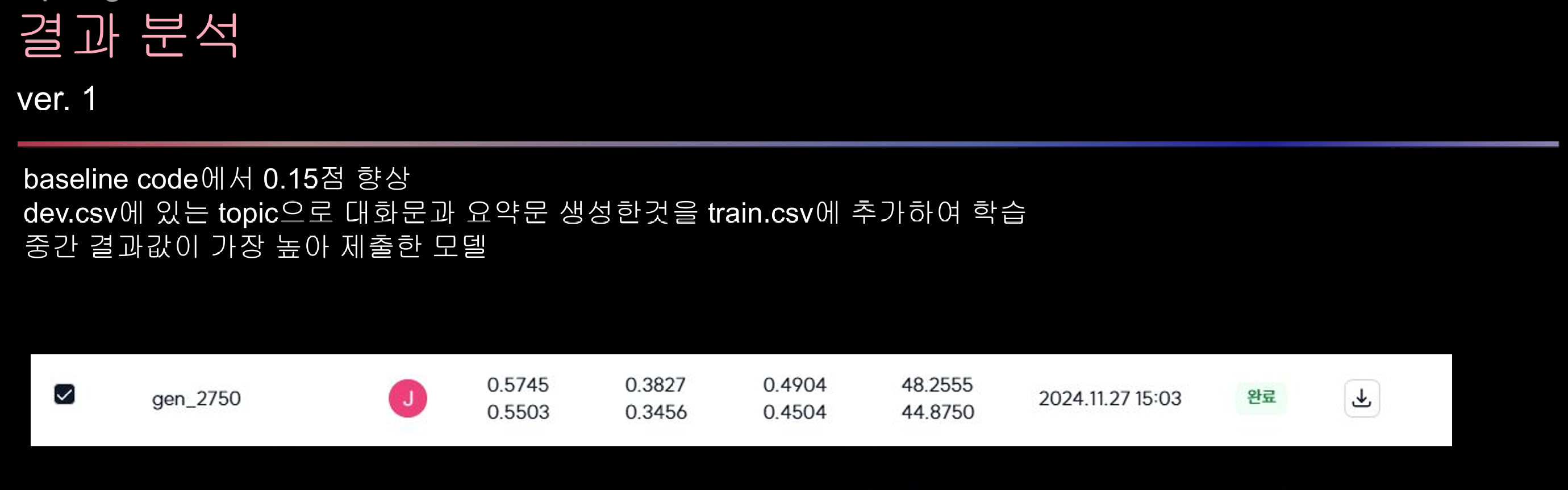
경진대회 개요
이번 경진대회의 목표는 일상 대화 데이터를 기반으로 자동 요약 모델을 개발하는 것이었다.
대화 데이터를 기반으로 효율적이고 정확한 요약문을 생성하는 NLP 모델을 구축하는 것이 주요 과제였다.
주제: Dialogue Summarization (일상 대화 요약)
주요 과제: 대화 중 요약이 어려운 문제를 해결하고, 자동 요약 모델을 개발하여 효율적인 정보 제공
제공된 데이터: 제공되는 데이터셋은 오직 "대화문과 요약문" : 회의, 일상 대화 등 다양한 주제를 가진 대화문과, 이에 대한 요약문을 포함하고 있음. input data: 249개의 대화문 / output data: 249개의 요약문
Evaluation Metric:
Rouge Score>> 요약, 기계 번역과 같은 태스크를 평가하기 위해 사용되는 대표적인 metric . 모델이 생성한 요약본 혹은 번역본을 사람이 만든 참조 요약본과 비교하여 점수를 계산.

경진대회 내에서 맡은 역할: Back Translation 및 Gemma, Prompt Engineering 실험
실험 진행 방식:
- 매일 오후 2시에 Zoom 미팅을 통해 각자의 실험 결과 공유 및 다음 실험 방향 설정
- 안정적인 방법과 실험적인 방법을 병행하여 다양한 시도를 진행
초반 모델 실험 및 최적화 과정
초반에는 팀원들과 모델 선정, 데이터 증강, 하이퍼파라미터 튜닝, Freezing 기법 등을 적용하며 최적화된 모델을 찾기 위해 노력했다.
우리 팀이 실험한 주요 모델은 다음과 같다.
| 모델 | 설명 | 결과 |
| KoBART | 한국어 요약을 위한 사전 학습된 Transformer 기반 모델 | 성능 저하 |
| BART-Summarization (EbanLee/kobart-summary-v3) | 문서 및 도서 요약용으로 파인튜닝된 KoBART 모델 | 베이스라인보다 성능 하락 |
| T5 모델 (keti-air/ke-t5-base) | 한국전자기술연구원의 한국어-영어 학습된 T5 모델 | OOM 문제로 실패 |
| Gemma 2-9B-it | Google Ko-Gemma 모델 | 메모리 이슈로 실패 |
- KoBART 기반 요약 모델을 실험했으나, 베이스라인보다 성능이 낮게 나왔다.
- T5 모델을 활용하려 했으나, 학습 시간이 오래 걸리고 GPU OOM 문제가 발생했다.
- Gemma 2-9B-it 모델을 활용해보려 했으나, 모델 크기 문제로 메모리 이슈 발생하여 실험 중단
데이터 증강 및 성능 최적화 과정
1) LLM 기반 데이터 증강
- Train 데이터셋에서 대화 주제를 추출하여 추가 데이터를 생성
- Solar-Pro 모델을 활용하여 topic별 대화를 생성하여 데이터 증강
>> 기대했던 효과:
- 다양한 대화 유형을 학습시켜 모델의 일반화 성능 향상
결과: 기대만큼의 성능 향상은 없었음
2) Back Translation 기법 적용
- Train 및 Dev 데이터셋이 영어 → 한국어로 번역된 상태여서
이를 다시 영어로 번역한 후, XSum을 이용해 요약 후 다시 한국어로 번역하는 방법을 시도
>> 시도한 방법:
- 초기에는 Helsinki Opus MT en-ko 모델을 사용했으나 Tokenizer 오류 발생
- 결국 GPT-4o API를 활용하여 번역 품질을 높이는 방향으로 전환
- 그러나 마지막 2일 동안 진행하여 시간 부족으로 실험을 제대로 진행하지 못함
교훈: 데이터 증강 과정에서도 충분한 시간을 확보해야 한다.
3) 모델 레이어 Freezing 실험
KoBART 모델의 경우, 모든 레이어를 학습하는 것이 과적합을 유발할 가능성이 있다고 판단하여 일부 레이어를 고정하는 실험을 진행했다.
실험한 방법:
| 방법 | 설명 | 결과 |
| 모든 레이어 학습 | 전체 모델을 학습 | 과적합 발생 가능 |
| 디코더만 학습 | 사전 학습된 인코더 특성을 유지 | 성능 저하 |
| 인코더/디코더 하위 50% 레이어 고정 | 기본적인 특성을 유지하면서 일부 학습 | 성능 개선 미미 |
결과: Freezing 실험을 진행했으나, 기존 KoBART보다 성능이 낮아 최종적으로 적용하지 않음


결과 및 Trouble Shooting
1. T5 모델 실험 실패 원인 분석
- T5 모델을 활용한 실험을 시도했으나, 1회 학습 시간이 너무 길었고, 의미 있는 결과를 내기 위해선 더 많은 학습이 필요했다.
- QLoRA를 활용하여 메모리 최적화를 시도했으나, 여전히 학습 진행 중 OOM 문제 발생
- 결국 T5 모델 실험은 중단
교훈: 로컬 환경에서 실행 가능한 모델인지 미리 테스트하고 실험 계획을 세워야 한다.
2. Gemma 2-9B-it 모델 실험 실패 원인 분석
- HuggingFace에서 Gemma 2-9B-it 모델이 한국어 성능이 좋다고 평가되어 테스트
- 그러나 모델 크기 문제로 GPU 메모리 부족
- LoRa config, 4bit/8bit 양자화 시도 및 하이퍼파라미터 조정
- 하지만 여전히 OOM 문제 해결 실패
결론: KoBART보다 더 나은 결과를 기대하기 어려워 실험 중단
3. Optuna 하이퍼파라미터 튜닝 실패
- Optuna를 활용하여 최적의 하이퍼파라미터 탐색을 진행했으나,
- 기존 학습한 모델을 그대로 불러와 실험을 하지 않았음
- 데이터 증강을 했으므로 학습 횟수를 늘려야 했으나 고려하지 않음
- 학습 시간과 메모리 오해로 인해 잘못된 실험 설계
교훈: 급하게 실험하지 말고, 정확한 실험 설계를 먼저 검토할 것.
최종 결과 및 회고
최종 결과:
- 데이터 증강, 하이퍼파라미터 튜닝, Freezing 기법 등을 시도했으나 기대만큼의 성능 향상은 어려웠음.
- KoBART 성능이 baseline보다 낮게 나와, 추가적인 개선이 필요함.
이번 경진대회를 통해 배운 점
1. NLP 경진대회에서 데이터 증강은 신중하게 진행해야 한다.
2. 실험 과정에서 GPU 메모리 사용량을 사전에 검토해야 한다.
3. 하이퍼파라미터 최적화는 올바른 실험 설계를 기반으로 진행해야 한다.
마무리하며
이번 대회에서 다양한 실험을 진행했지만, 결과적으로 기대한 만큼의 성능 향상은 어려웠다.
특히 메모리 부족 문제와 실험 설계의 중요성을 다시 한번 깨닫게 되었다.
향후에는 메모리 최적화가 가능한 경량 모델을 활용하거나, 멀티모달 접근법을 고려하는 것도 좋은 방향이 될 것이라고 생각한다.
그리고 학과 과정에서 NLP를 들어서 이번 경진대회에서 나름 결과를 좋게 만들 수 있을 줄 알았지만 결과는 여태 진행되어왔던 모든 경진대회에서 성적이 제일 안좋았고 (3년 전쯤 원초적인 NLP (품사 태깅 및 텍스트 전처리, 분석 등) 기초적인 부분을 배웠고 현재 훨씬 많은 발전을 이뤄서 대규모로 처리 가능한 그리고 한국어로는 처음 번역 및 요약을 T5, Bert, GPT등 여러 모델들이 나온 이상 앞으로는 더욱 빠르게 발전할 것이라 예상하기에 더욱 정진해야할 필요가 있다고 느꼈다.
'AI' 카테고리의 다른 글
| <14일차> RS(Recommend System) 프로젝트 회고.. (0) | 2025.03.13 |
|---|---|
| <13일차> IR 경진대회 회고 (0) | 2025.03.13 |
| <10,11일차> Computer vision / 경진대회 진행 (0) | 2024.11.08 |
| <9일차> MLops Project... (2) | 2024.10.11 |
| <8일차> Mlflow, FastApi, Bertmodel, Airflow ... (2) | 2024.09.25 |