한달동안 computer vision에 대해 학습(강의) 및 경진대회 2주를 진행하면서 느낀 점을 적어보려고 한다.
일단 가장 먼저 앞서 여러 프로젝트와 ml 경진대회 한번 겪으면서 진행했던 머신러닝 모델 과정에서 모델을 한번 돌렸을 때 train set의 sample 수가 많거나(이것저것 적용을 하면서) one epoch당 결과를 k-fold로 여러번의 검증을 한다던가 식으로 했을 때 압도적으로 시간이 다 돌리고 만약 위에 있던 코드에서 에러가 터져서 모델을 다시 돌려야했을때의 time management가 매우 힘들었음을 느꼈다. 초반 test 과정에선 이것저것 하이퍼파리미터던지 모델이던지 쉽게쉽게 금방 변경해서 test가 가능했는데 후반에 train set을 증강시킨다던지(offline)으로 task가 늘어나면 날수록 한번 돌리는데 6시간씩 진행되어서 마지막 2일에는 많이 빡빡했음을 느꼈다.
일단 간단하게 이번 경진대회의 mission은 train set에 있는 1570개의 이미지를 17개의 카테고리로 머신러닝 모델로 학습하여서 분류한 결과를 바탕으로 이 모델을 cv 인사이트를 적용해서 얼마나 test set에 있는 3140개의 이미지를 잘 예측하느냐가 관건인 경진대회였다.

채점 스코어는 macro f1으로
결과적으로 각 클래스마다 f1 score을 얼마나 잘 끌어올렸느냐가(궁극적으로 전체 f1) 등수를 가르는 판단지표로 쓸 수 있겠다.
초반에는 나와 팀원들 모두 모델 및 하이퍼파라미터, augmentation(transform)에 집중하여 최적화된 샘플을 찾으려고 노력했다. Google sheet에 각자 모델 테스트를 및 하이퍼파라미터 테스트를 진행한 결과를 공유했고 다른 팀원이 여러 모델(단순히 모델 성능 비교) 을 테스트 해보면서 convnext를 하기 직전엔 efficientnet 모델이 가장 성능이 높게 나왔어서 나는 tf-efficient 모델 베이스로 잡고 돌려보기로 진행했다.
Hiera 모델 : 0.3762/0.3805
VIT 모델 : 0.5444/0.5469
Tf-Efficient 모델 : 0.5775/0.5659
Efficient-VIT 모델 : 0.6183/0.6361
Convnext 모델 : 0.7001/0.7299
각자 모델성능의 하이퍼파라미터를 기록해둔 것을 기반으로 나는 최적의 하이퍼파라미터를 찾을수 있었고(메모리 문제로 물론 여러번 터져서 많이 낮춰야했지만) 일단 초반에 올릴 수 있었던 결과는 다음과 같다.
img size, batch size, LR 등을 조절 후에 epoch도 10에서 30으로 늘렸고 transform도 여러 기법을 이용해서 적용시켰다.

학습 스케쥴러, optimizer도 AdamW으로 변경했고 mixed precision training 등 최적화를 시도한 결과 0.80까지 끌어올릴 수 있었다. 하지만 여기서 더 이상 모델만으로 끌어올릴 수 있는 방법이 도저히 보이질 않아서 EDA를 다시 시도해보기로 결정했고 갑자기 드는 생각이 1570개의 train set이 학습하기에는 저 이것저것 적용한 transform을 다 적용시키기에 무리가 있을수도 있겠다 라고 판단되어서 다시 한번 클래스별로 sample frequency를 살펴보고 오버샘플링을 하기로 마음먹었다.
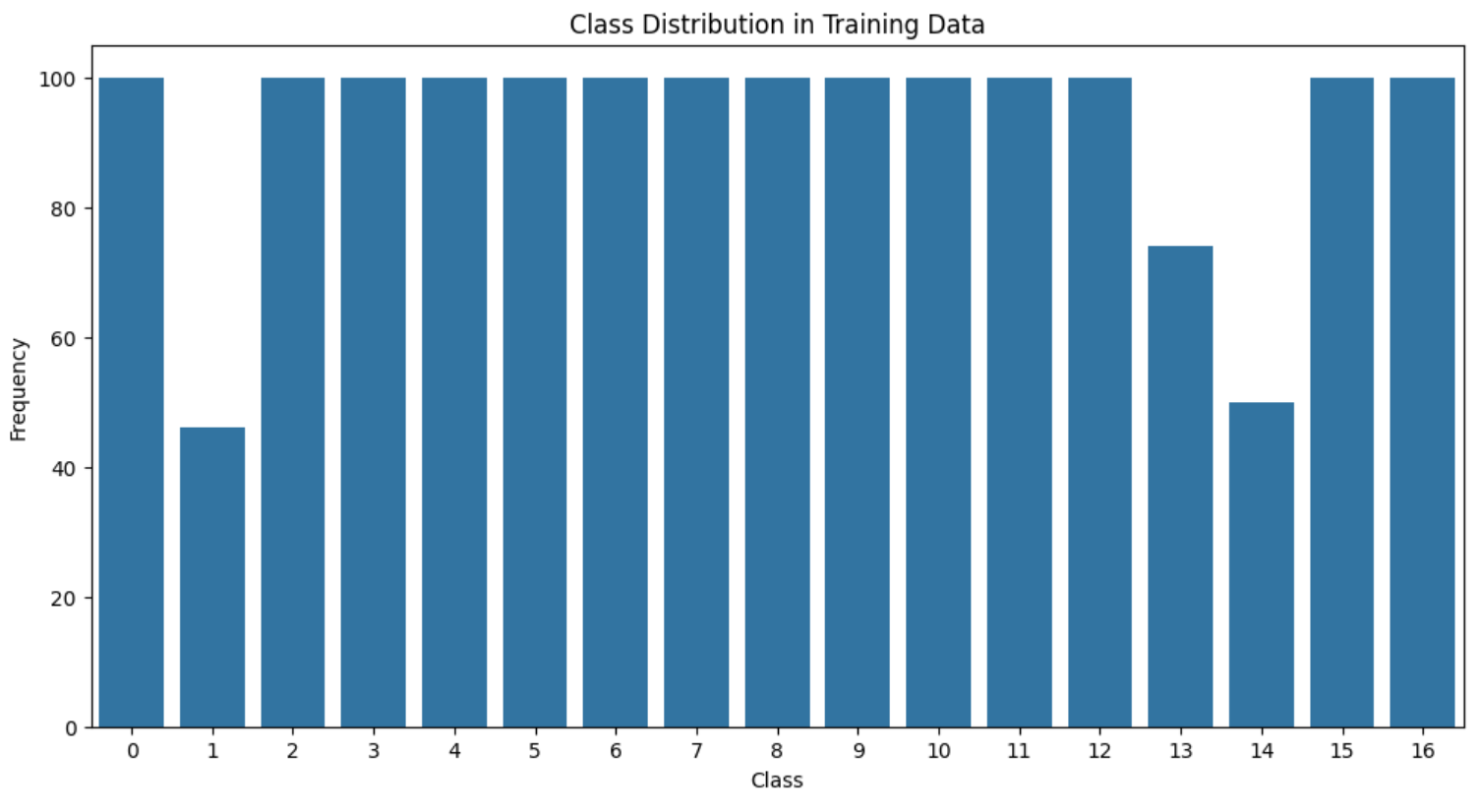
진행했던 방향은 모자랐던 class 1,13,14에 130개를 채워서 총 1700개로 맞춘다음 max_sample로 2배,3배,4배로 배율조정을 하면서 온라인 증강을 시도하였다. 그결과 f1 score가 0.89 -> 0.903 -> 0.9306 으로 올라갈수 있었지만 (여기서 모델 및 하이퍼파라미터 수정) 또 한번 0.92-0.93 늪에서 헤어나올 수 없었다. 원인이 무엇일가 분석해보다가 클래스별로 f1 score를 한번 찍어보자라는 생각이 들었고 (macro - f1이기 때문) 결과론적으로 class 3,4,7,14의 f1 스코어가 현저히 떨어지는 것을 확인할 수 있었다.
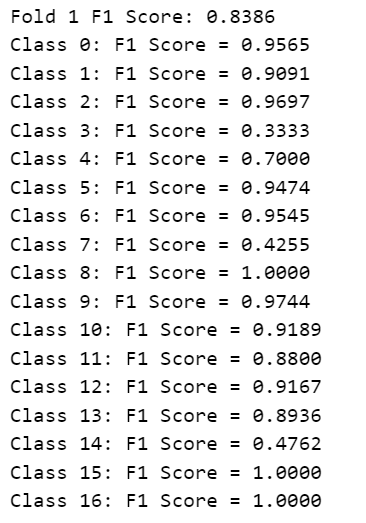
train set에 있는 class 3, 4 ,7, 14를 보면서 무엇 때문에 결과가 이럴까 분석해보니 4개의 클래스가 전부 문서인데 비슷한 내용을 담고 있어서(ex. 확인서, 증명서 등) 머신러닝 모델이 분석이 쉽지 않았으리라 판단이 들었다. 그리고 test set에 있던 일부 이미지들도 심한 blur 처리 및 고의로 안보이게 해놓는 처리가 되어있어서 잘 분류하기가 힘들었을 거라고 생각한다. 그래서 가장 먼저 들었던 생각이 OCR로 (tf-idf, pytesseract) 로 text로 분석한 다음에 이 글자들을 저 class별의 문자에 맞게 학습시키면 f1 score가 오르지 않을까 생각이 들었다.
그래서 text와 text_vector( augraphy 적용시킨) 를 담은 multimodal로 모델을 학습 진행 시켰지만 생각보다 결과가 미미하게 나왔고 아무래도 이것 역시 test set의 글자를 쉽게 읽기 힘들어서 더 그랬던 것 같다. (0.9306->0.9366) (+클래스별로 텍스트 가중치 1.5배, 모델에서 3,4,7,14, 집중적으로 weight 주기 등)
이 것이 내가 만든 베이스라인 코드였고 이 코드를 기반으로 다른 팀원들과 함께 좀더 f1 score를 올려보자 라는 의견이 나왔다. 결국 다른 팀원이 cutout의 미세조정을 통해 (class 3,4,7,14의 cutout 비율조정) 0.9386까지 올릴수 있었지만 0.94이상으로 올릴 수 있는 방법이 막상 더 떠오르지 않아서 멘토링을 통해 더 좋은 방법이 없을까 고민하던 찰나에 멘토 분께서 지금 온라인으로 증강하고 있지만 오프라인으로 증강해보면서 mixup등 다양한 시도를 해보면 좋겠다 라고 말씀하셔서 train set을 좀더 집중해보자 라는 생각이 들었다.
결국 오프라인 증강을 통해 대략 38000개 정도의 이미지를 transform을 통해 저장하였고(여기선 간단한 flip, rotate등만 적용) 오프라인으로만 0.9110이라는 f1 score를 받자마자 온라인+오프라인으로 학습시키면 더욱 효과가 좋을 거 같단 생각이 들어서 총 45000개로 학습을 시켜보았다. 이 과정에서 한번 모델을 돌릴때마다 무려 6시간이 넘게 걸렸지만 최종적으로 0.9540 / 0.9478로 최종 마무리 할 수 있었다.
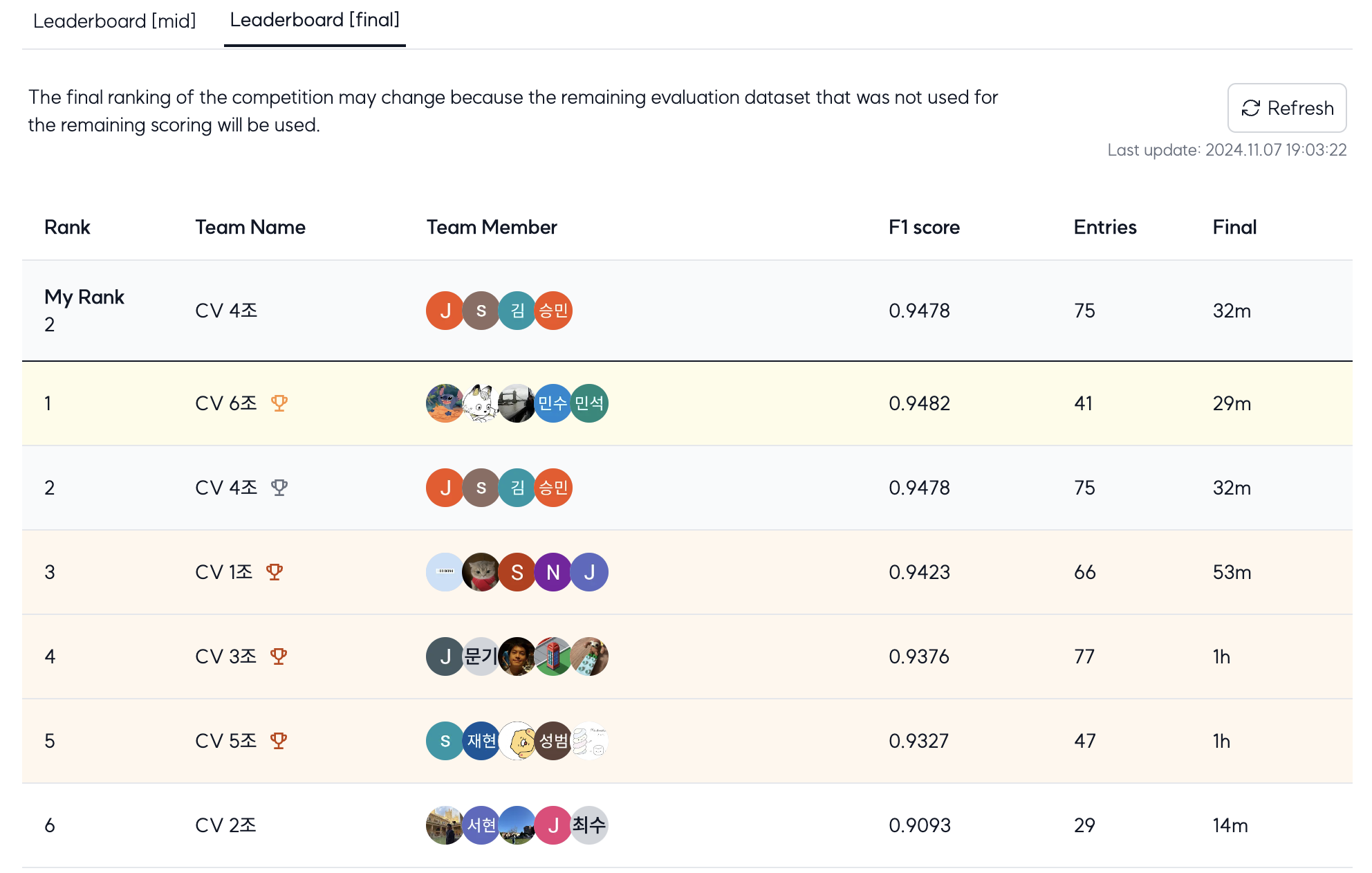
EDA부터, augmentation, baseline code를 맡으면서 정말 CV에 대해서 단순 온라인 강의보다도(물론 온라인 강의에서 기본 cv의 프로세스 및 적용 과정을 다 배웠지만) 더 많은 걸 배웠다고 생각하고 멘토님께서 말씀하신 것처럼 아직까지 실질적으로 human 이 더 잘 분류할수 있는 것이 많다는 게 맞다고 생각이 드는 과정이었다. 특히 document 식으로 비슷한 내용이지만 조금씩 다르게 분류될 수 있는 이 클래스들에 대해서 어떻게 하면 더 잘 분류해볼수 있을까에 대한 많은 생각을 할 수 있었고 또렷히 찍히는 이미지들은 이 비슷한 클래스들끼리도 분류가 잘되지만 blur 처리나 잘려 있는 이미지들 (crop) 그리고 transform을 어떻게 더 잘 적용시키면 좋을지 전체적으로 EDA, 모델 학습, 그리고 결과까지 CV에 대해서 얻을 게 많았던 경진대회라고 생각한다.
'AI' 카테고리의 다른 글
| <13일차> IR 경진대회 회고 (0) | 2025.03.13 |
|---|---|
| <12일차> NLP 경진대회 (0) | 2025.03.13 |
| <9일차> MLops Project... (2) | 2024.10.11 |
| <8일차> Mlflow, FastApi, Bertmodel, Airflow ... (2) | 2024.09.25 |
| <7일차> ML 경진대회 : Regression Wrap up (5) | 2024.09.20 |